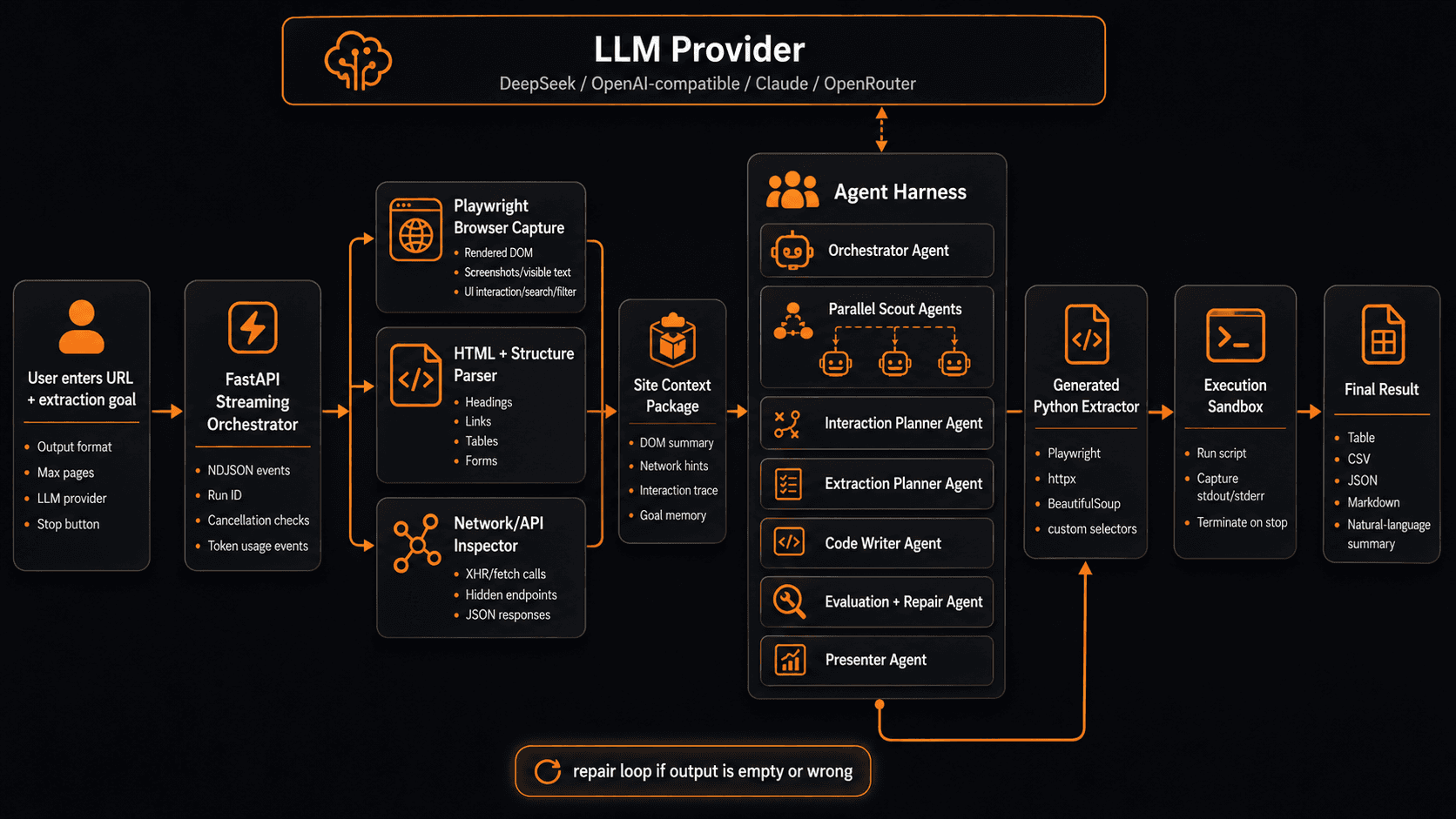
Open Extractor Agent is a local web app for turning public websites into structured data. You give it a URL and a plain-English goal, then it builds the extraction pipeline in front of you: capture, scouts, planner, code writer, execution, presenter.
The point is not only scraping. The point is inspectability. You can watch the flow diagram, read the plan, inspect the generated Python, see the raw trace, stop a run, and understand why the agent produced the result.
at a glance
the shape of it
- main job
- turn a public URL and plain-English request into structured data
- runtime
- local FastAPI web app, opened in your browser
- capture
- Playwright for JS-rendered pages, httpx for simpler fetches
- agent flow
- structure capture, parallel scouts, planner, code writer, execution, presenter
- outputs
- CSV, HTML table, JSON, Markdown, table views, downloadable results
- providers
- OpenAI, Claude, DeepSeek, Grok, MiniMax, OpenRouter, custom endpoints
- visibility
- live SVG flow, token events, stop control, inspector, generated Python
- license
- open-source · MIT
what it does
describe the data, get the file
It is built for the messy first pass: you know the website and the data you need, but you do not want to hand-write selectors before you have even proven the extraction works.
URL
extract every product name, price, rating, and detail link as CSVURL
crawl all pages and return a clean table of job titles, companies, and apply linksURL
find every pricing tier, feature, and limit, then return JSONURL
collect article titles, authors, dates, tags, and canonical linksURL
extract forms, hidden fields, API hints, and visible table dataURL
summarize the result and give me a Markdown table I can paste into Notion